Querying Ukrainian Geodata via AWS Athena
The smartphone war: -
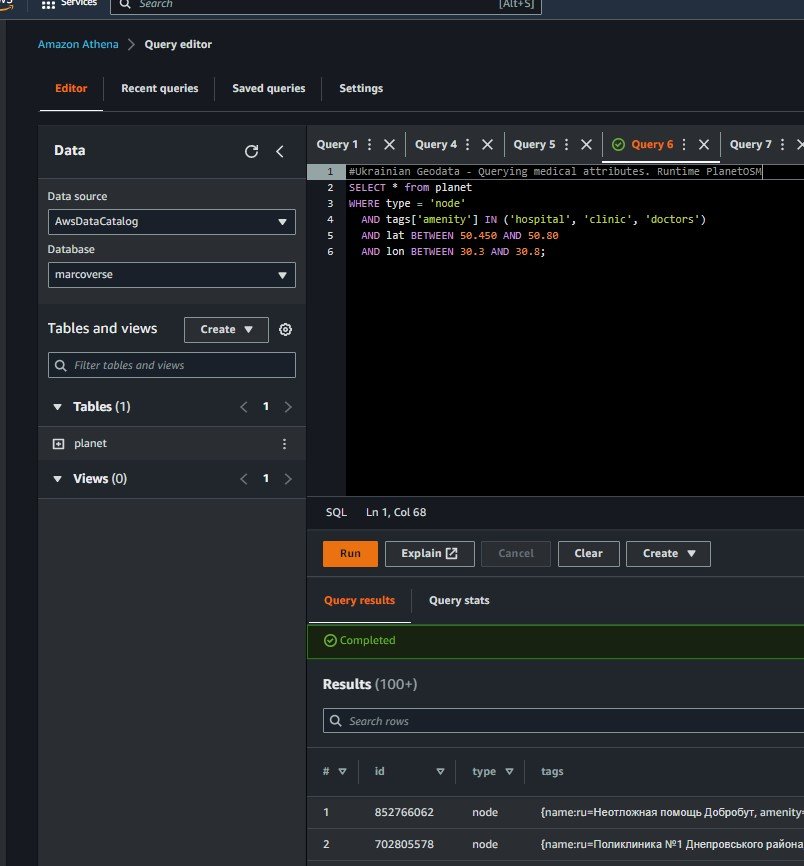
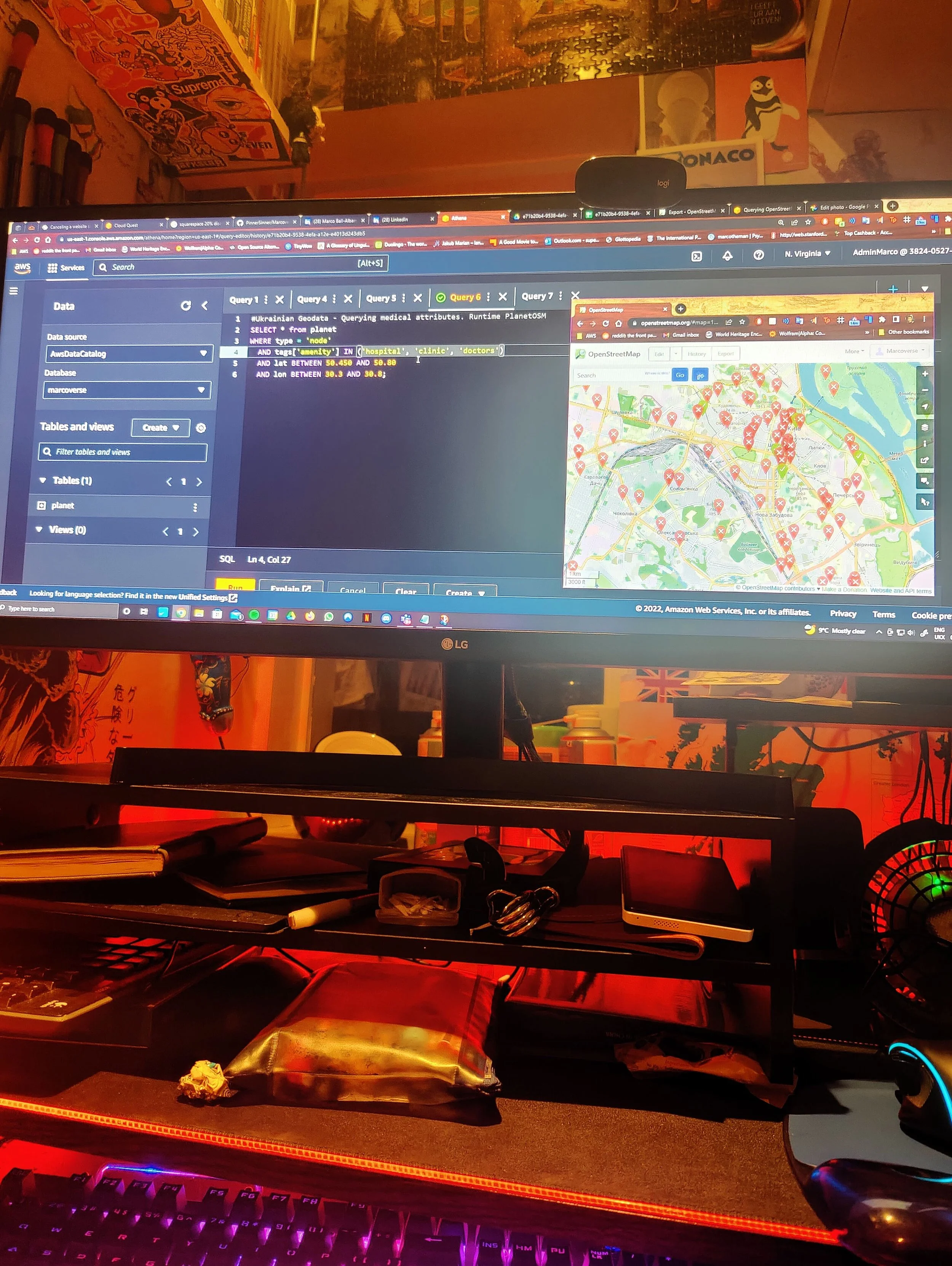
Using AWS Athena to query the Open Street Map public database to locate local services

The smartphone war
What I want to do here is quickly get you up to speed on what is happening and how these smartphones have been turned into a weapon in a weird version of hybrid warfare.
So I'm gonna walk you through the moves and the counter moves of this hybrid war so that we can understand how strategists have turned the internet into a weapon of war, and what's possible for me to do on AWS for relief.
-
We call it hybrid because you have two things going on here. You've got this traditional old school style war playing out, in which there’s artillery, foot soldiers and cruelty against civilians - all to annex the regions of Donetsk & Kherson. That's old school style war.
-
And yet Putin hasn't declared an official war. He's covering this whole thing up back home calling it a special military operation, while simultaneously stealing a bunch of land in Ukraine and drafting hundreds of thousands of Russians to the battlefield.
-
As someone who studies technology, this has gripped me because it's playing out not just on these battlefields but on a bunch of other battlefields too. Energy markets, infrastructure, financial systems and information sharing on the internet that simply has never existed before like this. And it's on these battlefields. where the big nuclear powers of our world are going head to head in an increasingly dangerous way.
-
MineFree is a mobile application developed by volunteers from the Swiss charity ‘Free Ukraine’, with the support of the State Emergency Service of Ukraine (SES).
With downloaders of the app collaborating, it protects civilians from the thousands of explosive devices distributed in different areas of Ukraine, now one of the most mined countries in the world .
Its users can access an interactive map with potentially dangerous areas marked in red, receive vibration and audio notifications in the event of approaching a suspected explosive object, and access photos and descriptions of the various artefacts found on Ukrainian soil.
-
Analysts from the Malwarebytes Threat Intelligence company describes phishing campaigns against the Russian government.
The goal being to infect government computers with a custom remote access Trojan (RAT) that likely aided in espionage operations.Incredibly, RuTube (the Russian state-backed alternative to YouTube) stopped working. Honestly, incredible work.
-
This is the most interesting rabbithole, in my opinion.
Both Ukranian and Russian government bodies have opted to plant face in social networks using memes on Twitter, Telegram, Reddit and indeed any platform to bet on disinformation and delegitimization of opposing media. This is the propaganda machine in action.
Humour is an international language, an escape valve for the worst tragedies and, for a country with an actual comedian at the helm, a very effective weapon indeed.
Since the beginning of the Russian invasion, Ukraine has devoted a large part of its efforts to developing all kinds of both offensive and defensive strategies.
Open source intelligence helps in understanding how war in Ukraine is unfolding:

This conflict has been amplified over thousands of Telegram channels, Twitter feeds and Reddit threads all over the world.
As an enthusiast of photography myself, I’ve been both haunted and fascinated by the quality of footage available. Even in the GoPro community, a viral video of a 4K UHD 60FPS POV Russian pilot ejecting from his helicopter has surfaced. I won’t share it here, since I refuse to glorify these broadcasts - but technology has redefined the battlefield.
People are acting as war reporters by the tens of thousands. This war is playing out on our phones in ways that no other conflicts ever has in human history.
Ultimately, the internet & rapid developments in technology are more capable to cause malice more than ever before. And often, the distinction between good/bad is hard to tell apart (I’ve been reading about Stuxnet this week).
Technology has mutated into a lethal weapon, capable of crippling the globe’s economy - for us all to see from behind our screens
That being said, I’ve leveraged the Ukrainian conflict as a case study to architect a solution through AWS
Project
-
The scenario for this demo is that I’m architecting an application for a number of mobile teams in the field. These teams are looking to locate and navigate to local relief shelters with GPS coordinates.
They need run ad-hoc queries to get a list of local relief centres (attributes such as ‘embassy’, ‘medical’, ‘shelter’, etc) clinics based on geographic areas.
They can’t tolerate any significant set-up time. Can’t have any base infrastructure costs and not maintain their own database. Considering the region’s instability, data isn’t necessarily safely stored in local FTP servers; downloading raw data and importing files up to 50GB in size into my team’s own systems (for map rendering, directions, or general analysis) would be ineffective.
In a nutshell, I’ll create an area of interest using GPS coordinates. Query this data through a schema to output insights, all without managing or incurring management overhead. It’s an ideal use-case for AWS Athena’s ‘schema on read feature’ to generate some important data for those in need of relief
-
I’ve chosen to source my data from open database maintained by OpenStreetMap (OSM or PlanetOSM). Regular OSM data archives are publicly corroborated, thus made available to us via planet.openstreetmap.org.
All in all, it’s an enormous repository of machine learning, translation and all sorts of wacky data, as big as 16petabytes in size. But for my purposes - and that my database literacy is definitely not up to scratch - is to concentrate on the PlanetOSM maps available in Apache ORC format for Amazon S3.
- This contains a number of different types of data. ‘Nodes’ are things inside the database (like business names, with location and other associated metadata). ‘Ways’ are boundaries/area based information, and ‘relationships’ stores relationships between others.
In a nutshell, it’s a free and editable map of the world. Corroborated by tech junkies around the world and made available for use under an open license. Supposedly, it’s used by non-profits in the field already in use-cases similar to my own, such as: the American Red Cross, the World bank and Mapbox to name but a few.
I want to access this data without creating/managing infra, which is why Athena is a good choice.
-
With Athena, I can use the OSM mapping data as a source. But rather than modifying it as any way, I can define a schema in advance through a process called ‘schema-on-read’. It’s a technique which doesn’t modify the original data, but defines a schema (structure) for the data.
This way, I can take unstructured data which I don’t want to own or want to manage, read it from S3 bucket, and actually display it through Athena all without extracting, transforming or loading the data.
Incredibly, Athena’s schema-on-read can ingest enormous data repositories and allow us to interact with it, generating meaningful insights typical of relational databases, all without burdening ourselves with the download. Sort of like a window.
Nothing to download, nothing to configure, nothing to host. Billions of data points at our disposal.
-
OSM is a free, editable map of the world, created and maintained by smart folk out there in the world. Check below for an embedded map of the sets I was working with.
Public datasets are actually taken out of their normal format and put it into an Apache ORC - a form of columnar datastore which is tailored for quick queries in the cloud.
-
Of course to perform any kind of data analysis, you first need data. It’s a necessary part to so much in research & ML nowadays for a variety of subjects (such as traffic, maps, medical, financial, sports, social data etc).
Privacy concerns largely prohibit the free distirbution of many data sets. Often, getting in the way of things when publicly available data is relatively scare to perform proper varied research.
Nonetheless, AWS have begun to host data set corpora from 2019 onwards.
This was my first exposure to BIG DATA repositories, but fortunately AWS makes it simple to access the public data sets.
Both AWS Glue as well as Athena allow me to create custom tables stored on my server space. I chose to download copies of the results to my local machine rather than keep my work in progress on my Amazon server. This is because I anticipated that the bandwidth for constant and consistent access wouldn’t be available - as in my scenario. -
Plus, we’re in control. S3 provides high availability for the data, and Athena’s window only charges a small amount per TB of data scanned.
Seth Fitzsimmons - a director on OMS whose tutorials to make this project work I’m eternally grateful for - says it best:
”All the hard work of transforming the data into something highly queryable and making it publicly available is done; you just need to bring some questions.”
🏥I swore to do no harm, so I settled on finding emergency relief shelters and medical facilities for users with impacted internet connectivity inside warzones.
My demonstration was prompted by the question:
“How can I make data better available” and “what sort of tweaks can I perform to analyse data in the cloud under stress?”


Considerations
-
- You can take data stored in S3 and perform Ad-hoc queries on data. Pay only for the data consumed (while running the query and storage for data in s3 - on demand billing for only what you use)
- Start off with structured, semi-structured and even unstructured data that is stored in its raw form on S3. Athena uses schema-on-read, the original data is never changed and remains on S3 in its original form. [see data through lens/window in certain way you want to, but original data unchanged and remains in S3 in original form].
- The schema which you define in advance, modifies data in flight when its read. Normally with databases, you need to make a table and then load the data in. But with Athena you create a schema and load data on this schema on the fly in a relational style way without changing the data.
- The output of a query can be sent to other services and can be performed in an event driven fully serverless way.
-
The source data is stored on S3 and Athena can read from this data. In Athena you are defining a way to get the original data and defining how it should show up for what you want to see.
Tables are defined in advance in a Data Catalog and data is projected through when read. It allows SQL-like queries on data without transforming the data itself.
Amazon’s Athena database supports a wide array of geospatial functionality that allows for building complex analysis with any data containing geographies or individual locations.
My objective is to query data directly from Athena and leverage all of OSM’s geospatial functionality to give users the ability to work with massive geospatial data sets.
-
Amazon’s Athena database supports a wide array of geospatial functionality that allows for building complex analysis with any data containing geographies or individual locations.
This data can be used in many ways: it can provide local geographic context (by being included in map source data) as well as facilitate investment by development agencies such as the World Bank.
My objective is to query data directly from Athena and leverage all of OSM’s geospatial functionality to give users the ability to work with massive geospatial data sets. It is a proof of concept work.
-
There’s an AWS Lambda function (running every 15 minutes, triggered by CloudWatch Events) that watches planet.openstreetmap.org for the presence of weekly updates (using rsync). If that function detects that a new version has become available, it submits a set of AWS Batch jobs to mirror, transcode, and place it as the “latest” version. Code for this is available at osm-pds-pipelines GitHub repo.
I haven’t explored this fully, but there’s a tool to facilitate the transcoding into a format appropriate for Athena (OSM2ORC), which would be great for more automated queries. It outputs a compatible ORC file that can be uploaded to S3 for use with Athena, or used locally with something like Hadoop.
-
I wanted to go through the experience of downloading publicly available datasets online, with map data from the conflict in Ukraine as an example.
As someone who would have to download ~20gb of update data to play his PS4 on a slow rural internet, often being estimated a wait-time of 3+ days, I absolutely understand the frustration of bottlenecking data transfers.
But now that I’m a little familiar with Athena and large public datasets, I can see how this is less of a problem. A clear roadmap of the necessary tasks also reduces the learning curve.Large amounts of data take time to download, as well as the compute power & space to manage it all. However, with advances like this, it’s less daunting than it was at the start of the project.

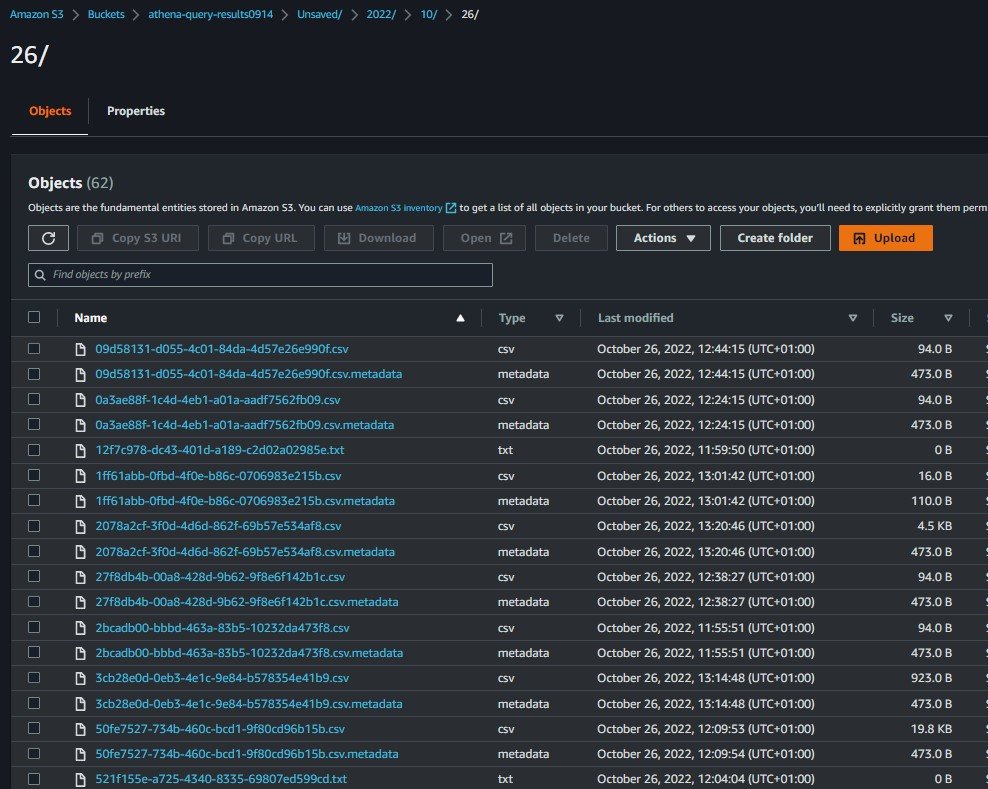
Before running queries, one must set up a query result location in S3 which will be used to output query results as part of interacting with Athena